A Logistic Regression Model with LASSO for the 2022 NCAA Tournament
March 15, 2022
One of the greatest sports weeks of the year, the first week of the NCAA basketball tournament, is upon us. From the unveiling of the bracket on Selection Sunday to the first games of the week, millions of Americans will scramble to fill out their tournament brackets for fun, fame, and (in some cases) prizes. For some, filling out a bracket is an annual ritual. Picks can be made “on a hunch”, after detailed study of the teams, or even based on the supposed ferocity of team mascots. However, picking game winners for the NCAA Tournament presents an ideal opportunity to apply analytics tools and techniques.
The analytics website Kaggle runs a data science competition focused on the NCAA Men’s Basketball Tournament Kaggle Competition (a competition for the Women’s tournament is also available). For 2022, the competition occurs in two phases. In the first phase, competitors were asked to build predictive models for historical NCAA Tournament results from the 2016, 2017, 2018, 2019, and 2021 tournaments (Note that the no tournament was held in 2020 due to the COVID-19 pandemic). This first phase gave competitors an opportunity to develop and test their models before entering the second phase. In the second phase, competitors submit predictions for the 2022 tournament. Submissions for the second phase are due before the first games tip-off on Thursday, March 17th.
Rather than simply predicting winners of these tournament games, competitors are asked to estimate the probability that each team in each game will win the game. For example, a model may assign a probability of 0.99 that a team with a seed of 1 willl defeat a team with a seed of 16. As the tournament unfolds, the quality of these predictions is evaluated by the “mean log loss” performance metric. Mean log loss is calculated by the formula below. In this formula, $y_i$ is the actual game result with a value of 1 indicating a win for team $i$ and a 0 indicating a loss. The value $p_i$ is the estimated probability of the team winning the game. Log losses for each of the $N$ games are then averaged to yield mean log loss. A perfect model would have a mean log loss of zero.
$$ -\frac{1}{N}\sum_{i=1}^{N}\left [ y_i\ ln\ p_i + (1-y_i)\ ln(1-p_i) \right ] $$
Being a sports fan and an analytics enthusiast, I took a little time to develop a few predictive models for the Kaggle competition. In this blog post I’ll focus on a logistic regression-based model. The logistic regression equation takes the form shown in the equation below. The $X$ variables are predictor variables and $p$ is the probability of the occurrence of the “positive class” of a binary response variable. In the case of our NCAA Tournament prediction model, the response variable indicates whether or not a team wins a game and the positive class of that variable is associated with the team winning (rather than losing) the game. We estimate the parameters $\beta$ and can then, given values for the $X$ variables, can solve for $p$.
$$ log\frac{p}{1-p}= \beta_0 + \beta_1X_1 + … + \beta_nX_n $$
Building such models is relatively easy, but not without its complications. Sports data often involves variables that are strongly correlated with each other. We can combat this multicollinearity by using a shrinkage and selection approach such as LASSO. LASSO applies a penalty parameter that can reduce the effects of predictor variables and can even drive the $\beta$ coefficients to zero. This would effectively eliminate variables from the model. Building a penalized version of a logistic regression model in R is easy with the “glmnet” and “tidymodels” packages.
The data used to build the model is from Bart Torvik’s excellent college basketball site Link. The variables that are initially in the model (before any variables are potentially removed by LASSO) are:
- Difference in Tournament Seed Between Teams A and B
- Torvik Power Rating (BARTHAG) for Teams A and B
- Adjusted Offensive Efficiency (ADJOE) for Teams A and B
- Adjusted Defensive Efficiency (ADJDE) for Teams A and B
- Effective Field Goal Percentage (EFG%) for Teams A and B
- Turnover Percentage (TOR) for Teams A and B
- Offensive Rebounding Percentage (ORB) for Teams A and B
- Free Throw Rate (FTR) for Teams A and B
The variables EFG%, TOR, ORB, and FTR are Dean Oliver’s “Four Factors” from his excellent book “Basketball on Paper”. All data is from the day following the NCAA Tournament Selection Show (Monday, March 14th, 2022). The objective of the model is to determine the probability that Team A will win a match-up with Team B.
The logistic regression model was built using cross-validation to select the “optimal” value of the penalty parameter $\lambda$. The resulting LASSO model retained the following variables: BARTHAG of Team A, the difference in seed between Team A and Team B, ADJOE of Team A, ADJOE of Team B, ADJDE of Team A, ADJDE of Team B, the EFG % of Team A, the FTR of Team A, and the FTR of Team B. The coefficients for the other variables were driven to zero, eliminating these variables from the model.
This model was then used to estimate the win probabilities for each match-up in the first (First Four) and second rounds of the 2022 NCAA Tournament. These results are presented in the table below. The results include all possible match-ups resulting from the First Four games. The table was created using the “gt” R package. Team logos are from the “ncaahoopR” package.
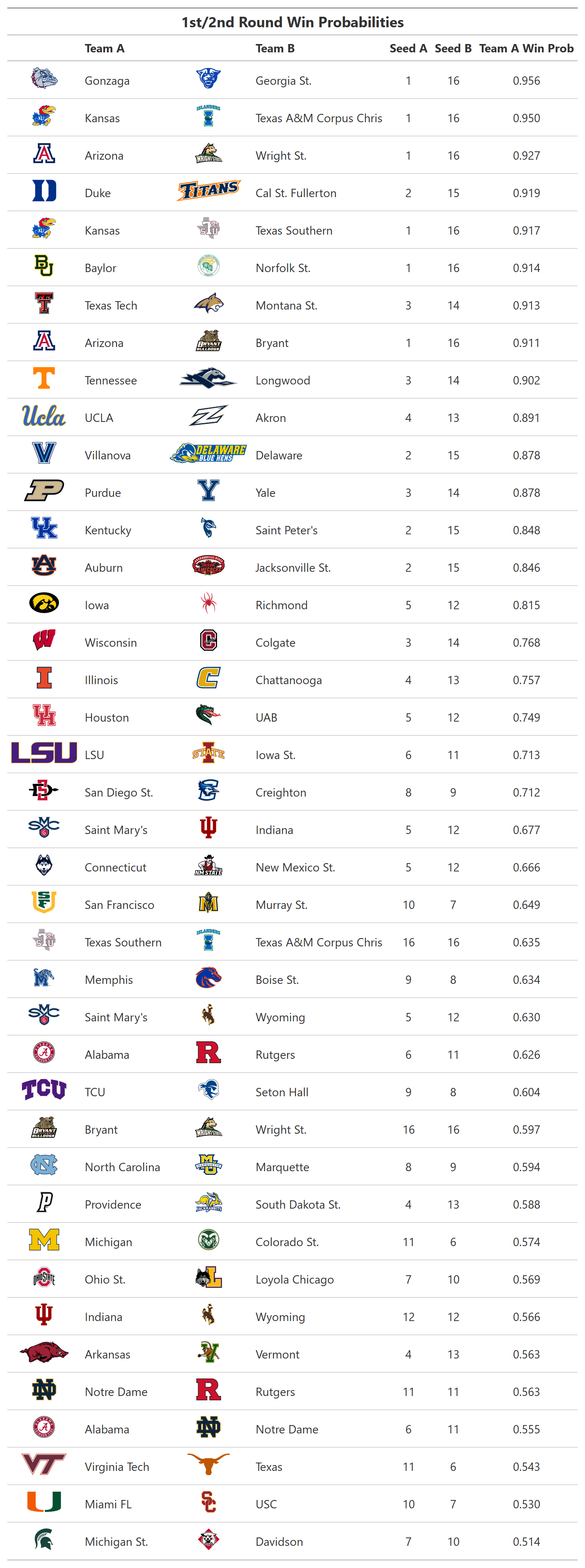
When tested on results from the 2016, 2017, 2018, 2019, and 2021 tournaments, this model resulted in a mean log loss of 0.54. This mean log loss would place in the “middle of the pack” of submissions in Phase 1 of the Kaggle competition, but performs well for such a basic model. Note that analytics-based models are often “chalky” in that they do not tend to predict “major” upsets. However, the model could be used to identify potential upsets.
If you are interested in learning more about building predictive models, I invite you to consider the Master of Business Analytics (MSBA) program at the University of North Carolina Wilmington. For more information on this program visit UNCW MSBA. For other training or consulting opportunities contact me by email stephen@lllumined.io or visit Illumined Analytics.